Case Study
University of the Arts, London
Delivering a Platform and API that connects collection items from different sources so that they can be presented in a single user interface.
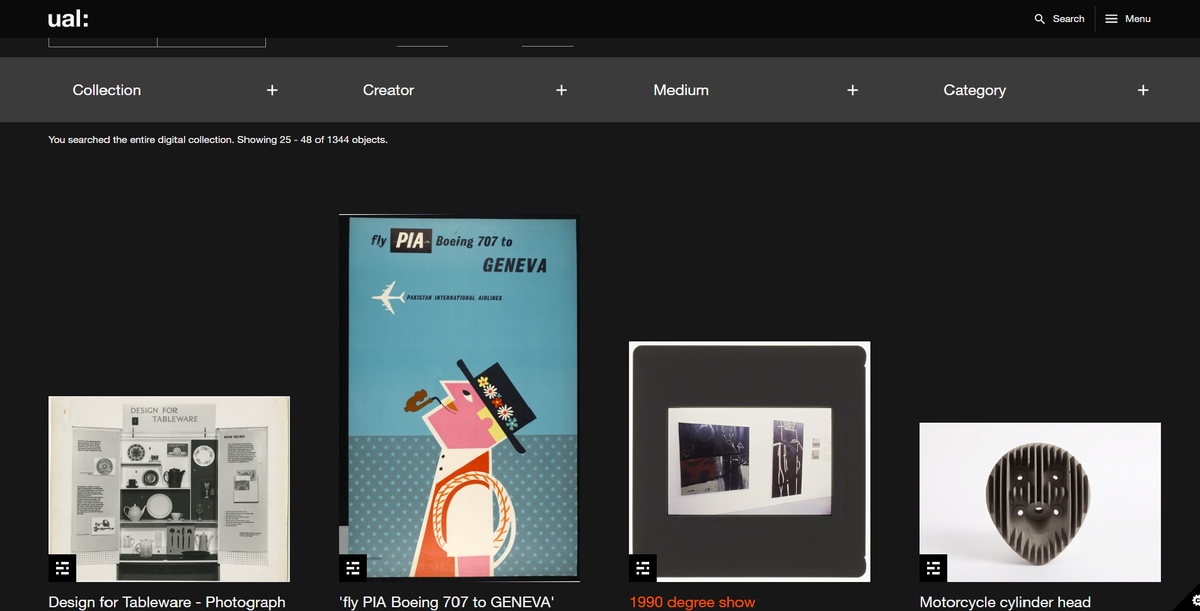
The technical landscape at University of the Arts, London (UAL) will be familiar to many institutions. A growing digitisation programme, multiple sources of descriptive metadata from library, archive and museum systems, a new digital preservation platform, and a desire to present digital collections in a single user interface that connects items from these different sources.
In UAL’s case the library catalogue is Koha, the Archive Management System is CALM, the Museum CMS is TMS, and the digital preservation platform is Preservica. The approach described here is applicable to many organisations with different components: a combination of introducing a IIIF service layer (our IIIF Cloud Services) and writing custom middleware to join these systems together.
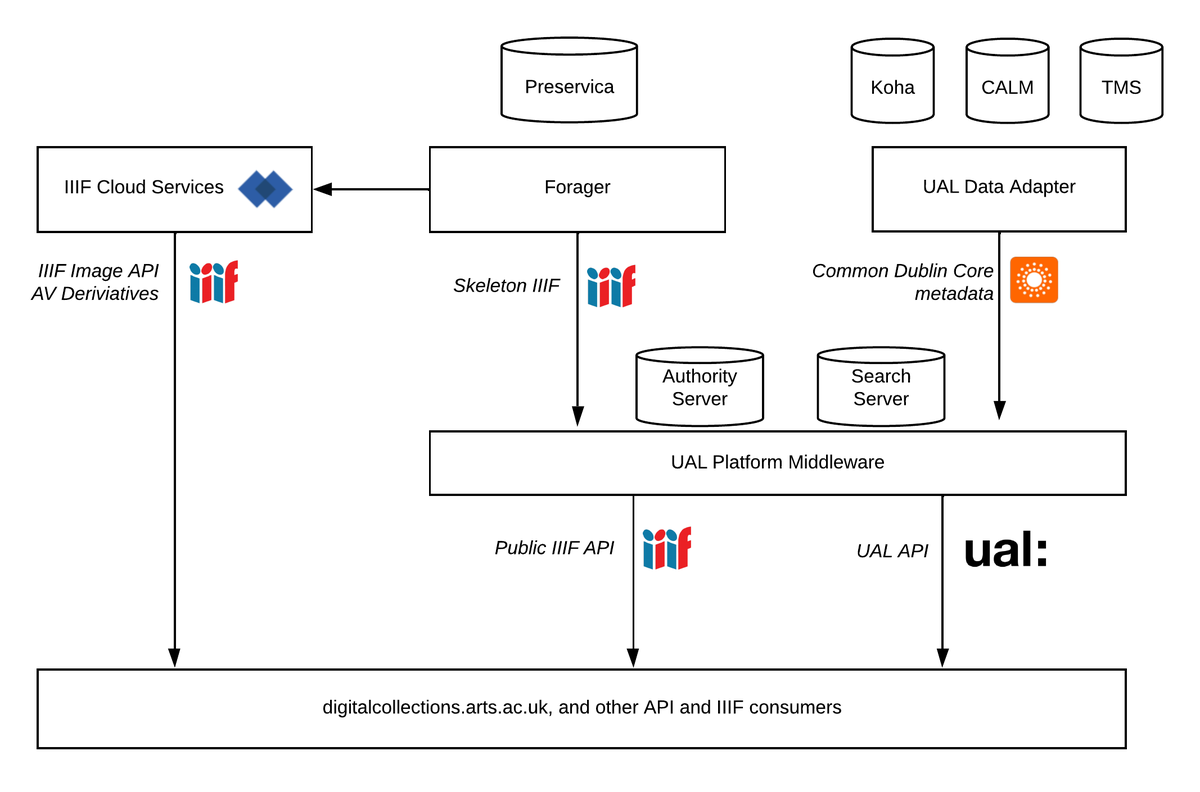 High level technical architecture
High level technical architecture
Our role in a project of this kind typically involves a division of work to suit the needs and capabilities of partners. In this case, we provided UX, data modelling, API design, technical architecture, IIIF hosting, and search and aggregation across collections using a combination of our existing software services and bespoke middleware. The Digital Collections site was developed by UAL (and continues to be enhanced by them); our task was to provide a UAL Collections Platform and API that met the immediate requirements of the new collections site but also anticipated future uses. To do this we needed to draw on the raw material for digital objects (TIFFs and AV files) stored in Preservica, and the descriptive metadata from the three different source systems provided to us in a data adapter built by UAL to an agreed Dublin Core metadata standard.
Using IIIF gives us a clear division of responsibility in various parts of the system; the assets in Preservica are ultimately the source of the visible digital objects (conveyed by IIIF Manifests) that users interact with on the site. And the records coming from the data adapter, fed by updates and changes in the three source systems, are the source of the content model, organisation, navigation and textual descriptions for those digital objects.
For the IIIF we make use of our Forager component. This listens to the Preservica API and synchronises its assets with our IIIF Services platform - creating IIIF Image API services from TIFFs (for deep zoom), and web-friendly derivatives for AV material. Forager understands which assets are part of an object, what order they go in, and what parent object they are part of (e.g., in an archival hierarchy). This purely structural information is enough for it to generate a skeleton IIIF Manifest for an object. Forager essentially provides a IIIF Collection and Manifest view over a Preservica repository, taking notice of access control metadata on the Preservica objects to generate IIIF Manifests that link to publicly available IIIF Image Services and AV derivatives, via our IIIF Cloud Services platform. Forager separates two distinct concerns: large-scale delivery of public IIIF, and Digital Preservation.
Forager notifies the UAL bespoke middleware whenever a source object is created, updated or deleted. Similarly, the UAL Data Adapter notifies the middleware whenever a source descriptive metadata record for an object changes.
From these two sources the middleware creates (and maintains through updates) enriched, connected IIIF Manifests and API entities - they have textual information from the source records, they understand shared subjects, people and other authorities, and they link to other objects and API records. The API also provides the operations for queries: faceting and free search, to drive the user interface.
Process
How did we arrive at this architecture and the shape of the API?
We started with some UX work to understand the different audiences and stakeholders and to inform a data model and API that allows UAL and others to build discovery and presentation layers for their collections, now and in the future. We are guided by previous work in generous interfaces across the cultural heritage domain, leaning on common patterns of querying, aggregation and presentation across many cultural heritage collections but also bringing out the particular quirks and characteristics of UAL’s own collections and metadata that influence the shape of the API.
One important principle in UAL’s case is that this API is not a replacement for the original descriptive metadata in the source systems. The MARC records, CALM item records and TMS objects are all still available. This platform API layer is specifically for driving user interfaces for discovering, viewing and understanding connections between items; we don’t conflate this with the much harder problem of producing a data model that fulfils the descriptive needs of the different library, archive and museum ways of looking at the world. We make use of IIIF’s clear distinction between presentation and description (IIIF is only for the former) to help us; we have IIIF to provide the data required to present an object, but we also need just enough description to power generous interfaces across these objects. This leads to a data model like this, which is partially realised in the current UAL Digital Collections site:
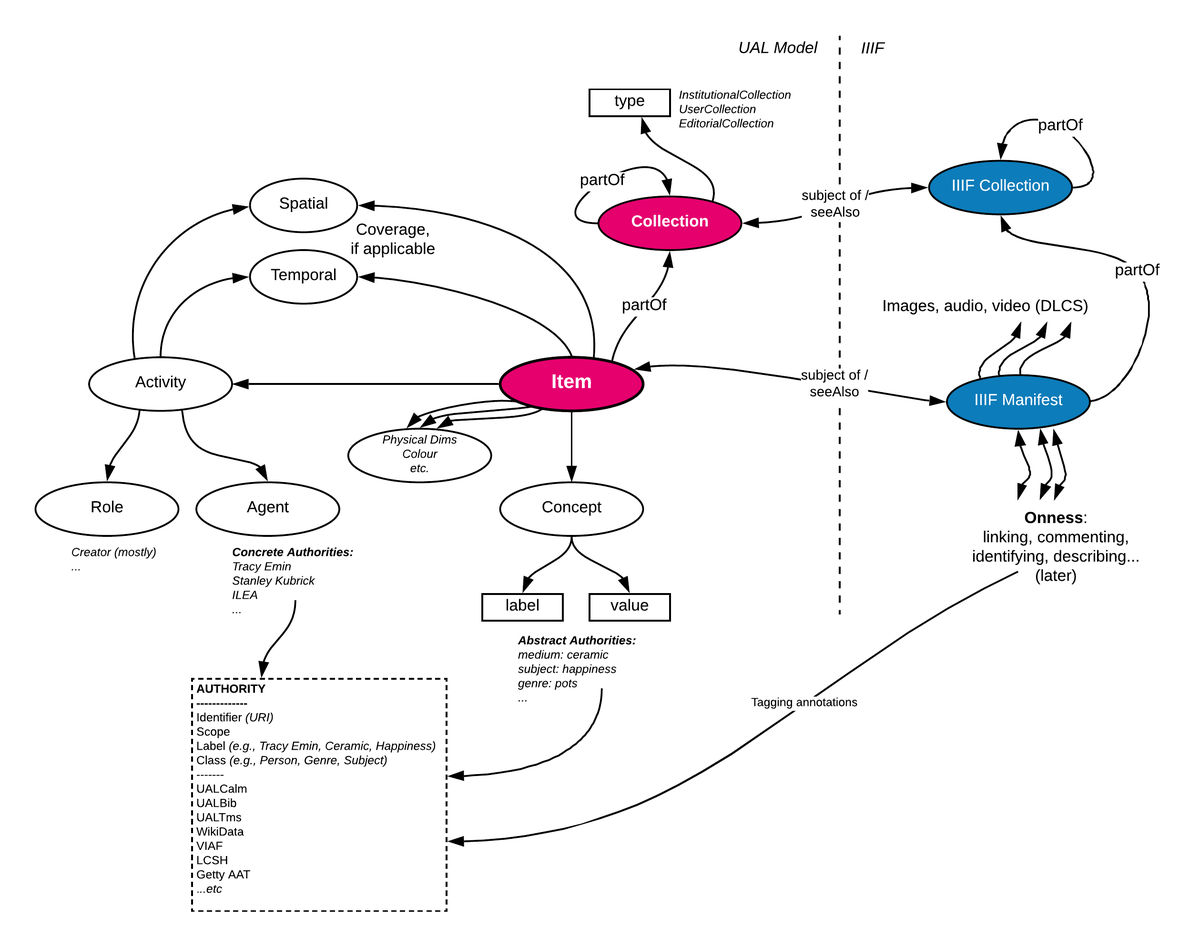 Data model
Data model
Central to this model, and essential for the ability to present objects from different sources, is the Authority Server - the most lightweight means of connecting a person or subject across the sources provided by the data adapter. This is one part of the middleware that has its own user interface, which allows UAL staff to examine the authorities the middleware has automatically identified and linked in incoming records, to merge and split authorities, and to introduce new linked authorities from external sources such as WikiData.
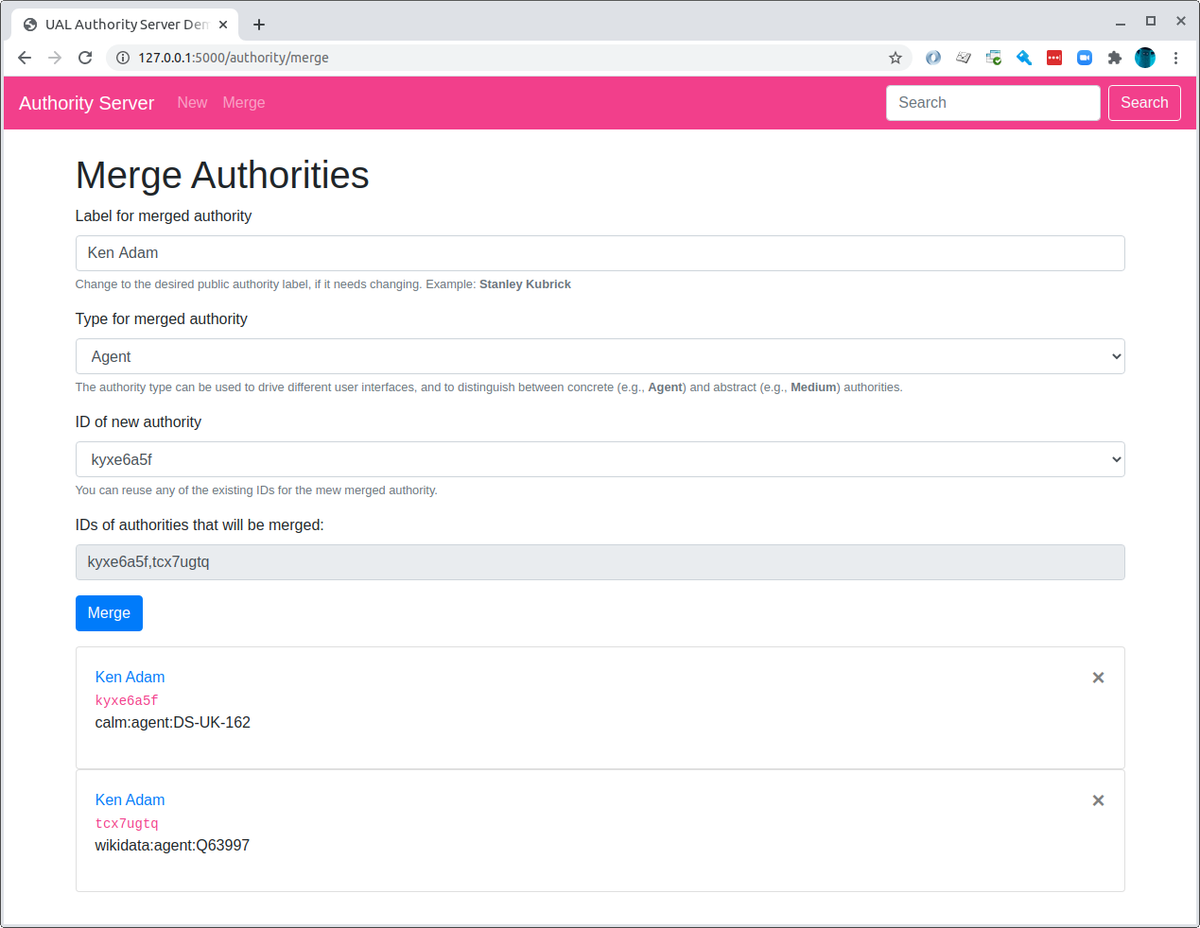 Merging authorities using the Authority Server
Merging authorities using the Authority Server
The platform middleware provides enriched IIIF Manifests, normalised API records across the different sources, and common identifiers for authorities. It also uses our Search Server, which indexes the records on their authorities, as well as free text. Queries to the search server are used to generate the views on the digital collections site, and can power user interfaces based on combinations of authorities, temporal extents and (later) geospatial extents.
Benefits
UAL gets the benefit of existing tools and platforms like our IIIF Cloud Services out of the box, as well as the Forager integration with Preservica. But they also benefit from a tailored platform, not a one-size-fits-all collections discovery interface. The API developed here allows for many different user interface treatments of the material, different discovery approaches, different IIIF viewers, different query-driven navigation and aggregation, by combining IIIF with a simple but powerful descriptive API that is specifically aimed at generating interfaces rather than satisfying the semantic needs of the many creators and consumers of the source data. The UAL developers working on the collections site are not dependent on Digirati to implement new user interface features.